This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Volume – Companies gather data from different sources such as business transactions, social media, and other relevant data. Variety – It means all data can be presented in a variety of formats – from structured numeric data to the unstructured ones, which include text documents, audio, video, and email.
What is Hevo Data and its Key Features Hevo is a data pipeline platform that simplifies data movement and integration across multiple data sources and destinations and can automatically sync data from various sources, such as databases, cloud storage, SaaS applications, or data streaming services, into databases and datawarehouses.
What is a Cloud DataWarehouse? Simply put, a cloud datawarehouse is a datawarehouse that exists in the cloud environment, capable of combining exabytes of data from multiple sources. A cloud datawarehouse is critical to make quick, data-driven decisions.
Dealing with Data is your window into the ways Data Teams are tackling the challenges of this new world to help their companies and their customers thrive. In recent years we’ve seen data become vastly more available to businesses. This has allowed companies to become more and more data driven in all areas of their business.
It provides many features for data integration and ETL. While Airbyte is a reputable tool, it lacks certain key features, such as built-in transformations and good documentation. Generative AI Support: Airbyte provides access to LLM frameworks and supports vector data to power generative AI applications. AI-powered data mapping.
Azure SQL DataWarehouse, now called Azure Synapse Analytics, is a powerful analytics and BI platform that enables organizations to process and analyze large volumes of data in a centralized place. However, this data is often scattered across different systems, making it difficult to consolidate and utilize effectively.
There are different types of data ingestion tools, each catering to the specific aspect of data handling. Standalone Data Ingestion Tools : These focus on efficiently capturing and delivering data to target systems like data lakes and datawarehouses.
MongoDB (or NoSQL) : An open source Database Management System (DBMS), MongoDB uses a document-oriented database model. That means that instead of using tables in rows in a database, MongoDB is made up of collections of documents. Get ready data engineers, now you need to have both AWS and Microsoft Azure to be considered up-to-date.
Unlocking the Potential of Amazon Redshift Amazon Redshift is a powerful cloud-based datawarehouse that enables quick and efficient processing and analysis of big data. Amazon Redshift can handle large volumes of data without sacrificing performance or scalability. What Is Amazon Redshift?
The pipeline includes stages such as data ingestion, extraction, transformation, validation, storage, analysis, and delivery. Technologies like ETL, batch processing, real-time streaming, and datawarehouses are used. They are ideal for handling historical data analysis, offline reporting, and batch-oriented tasks.
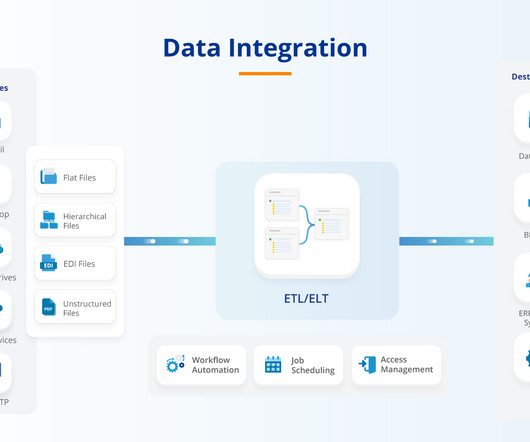
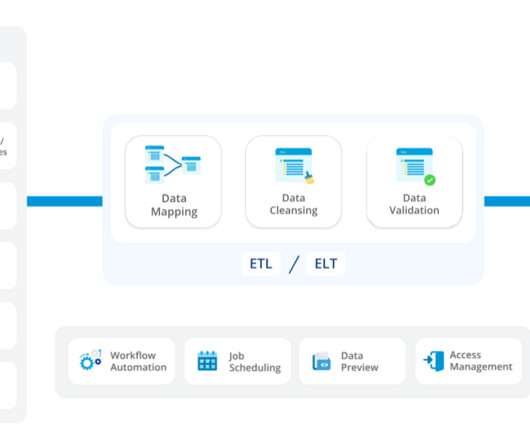
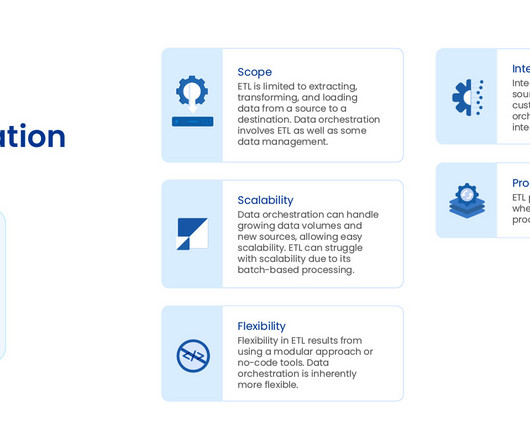
Common methods include Extract, Transform, and Load (ETL), Extract, Load, and Transform (ELT), data replication, and Change Data Capture (CDC). Each of these methods serves a unique purpose and is chosen based on factors such as the volume of data, the complexity of the data structures, and the need for real-timedata availability.
Enforces data quality standards through transformations and cleansing as part of the integration process. Use Cases Use cases include data lakes and datawarehouses for storage and initial processing. Use cases include creating datawarehouses, data marts, and consolidated data views for analytics and reporting.
Enforces data quality standards through transformations and cleansing as part of the integration process. Use Cases Use cases include data lakes and datawarehouses for storage and initial processing. Use cases include creating datawarehouses, data marts, and consolidated data views for analytics and reporting.
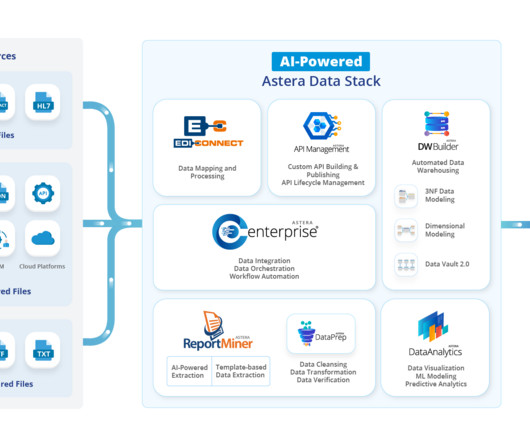
Building upon the strengths of its predecessor, Data Vault 2.0 elevates datawarehouse automation by introducing enhanced scalability, agility, and adaptability. It’s designed to efficiently handle and process vast volumes of diverse data, providing a unified and organized view of information. Additionally, Data Vault 2.0
So while there is a lot of power in having your data stored within Domo as a high performing, highly scalable, cloud-based datawarehouse, there is significant additional value in easily being able to get data out of Domo. Any customer who wants to get their data out of Domo can do so in a number of ways.
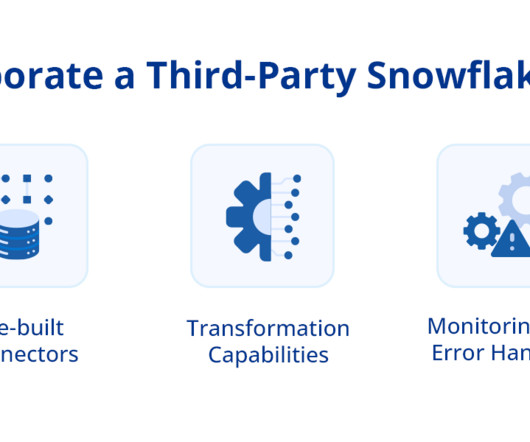
It eliminates the need for complex infrastructure management, resulting in streamlined operations. According to a recent Gartner survey, 85% of enterprises now use cloud-based datawarehouses like Snowflake for their analytics needs. What are Snowflake ETL Tools? Snowflake ETL tools are not a specific category of ETL tools.
Moreover, traditional, legacy systems make it difficult to integrate with newer, cloud-based systems, exacerbating the challenge of EHR/EMR data integration. The lack of interoperability among healthcare systems and providers is another aspect that makes real-timedata sharing difficult.
IoT systems are another significant driver of Big Data. Many businesses move their data to the cloud to overcome this problem. Cloud-based datawarehouses are becoming increasingly popular for storing large amounts of data. Challenge#4: Analyzing unstructured data. Challenge#5: Maintaining data quality.
IoT systems are another significant driver of Big Data. Many businesses move their data to the cloud to overcome this problem. Cloud-based datawarehouses are becoming increasingly popular for storing large amounts of data. Challenge#4: Analyzing unstructured data. Challenge#5: Maintaining data quality.
IoT systems are another significant driver of Big Data. Many businesses move their data to the cloud to overcome this problem. Cloud-based datawarehouses are becoming increasingly popular for storing large amounts of data. Challenge#4: Analyzing unstructured data. Challenge#5: Maintaining data quality.
Push-down ELT technology: Matillion utilizes push-down ELT technology, which pushes transformations down to the datawarehouse for efficient processing. Automation and scheduling: You can automate data pipelines and schedule them to run at specific times. This increases the learning curve of the tool and time-to-insight.
Different Types of Data Pipelines: Batch Data Pipeline: Processes data in scheduled intervals, ideal for non-real-time analysis and efficient handling of large data volumes. Real-timeData Pipeline: Handles data in a streaming fashion, essential for time-sensitive applications and immediate insights.
Different Types of Data Pipelines: Batch Data Pipeline: Processes data in scheduled intervals, ideal for non-real-time analysis and efficient handling of large data volumes. Real-timeData Pipeline: Handles data in a streaming fashion, essential for time-sensitive applications and immediate insights.
Different Types of Data Pipelines: Batch Data Pipeline: Processes data in scheduled intervals, ideal for non-real-time analysis and efficient handling of large data volumes. Real-timeData Pipeline: Handles data in a streaming fashion, essential for time-sensitive applications and immediate insights.
Data Loading The IT team configures a secure connection to BankX’s datawarehouse using Astera’s Data Connectors. Astera has native connectors for various datawarehouses, such as Amazon Redshift, Google BigQuery, or Snowflake, and can also load data into other destinations, such as files, databases, etc.
The transformation layer applies cleansing, filtering, and data manipulation techniques, while the loading layer transfers the transformed data to a target repository, such as a datawarehouse or data lake. Types of ETL Architectures Batch ETL Architecture: Data is processed at scheduled intervals.
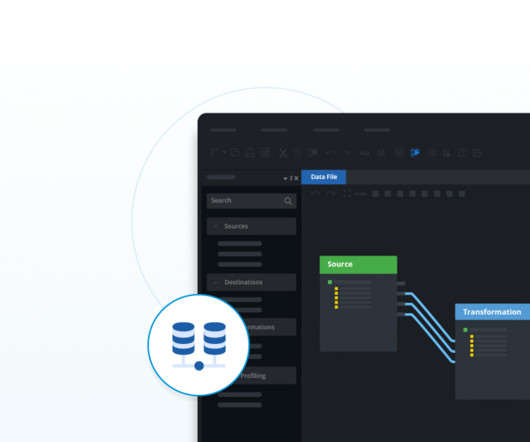
At its core, it is a set of processes and tools that enables businesses to extract raw data from multiple source systems, transform it to fit their needs, and load it into a destination system for various data-driven initiatives. The target system is most commonly either a database, a datawarehouse, or a data lake.
Data Loading Once you’ve have ensured data quality, you must configure a secure connection to the bank’s datawarehouse using Astera’s Data Connectors. Astera’s Data Destinations can be critical in setting up the credit risk assessment pipelines. Transformation features.
However, with SQL Server change data capture , the system identifies and extracts the newly added customer information from existing ones in real-time, often employed in datawarehouses, where keeping data updated is essential for analytics and reporting. Stay ahead of the curve with real-timedata updates.
Shortcomings in Complete Data Management : While MuleSoft excels in integration and connectivity, it falls short of being an end-to-end data management platform. Notably, MuleSoft lacks built-in capabilities for AI-powered data extraction and the direct construction of datawarehouses.
A research study shows that businesses that engage in data-driven decision-making experience 5 to 6 percent growth in their productivity. These data extraction tools are now a necessity for majority organizations. Extract Data from Unstructured Documents with ReportMiner. What is Data Extraction? Data Mining.
Free Download Here’s what the data management process generally looks like: Gathering Data: The process begins with the collection of raw data from various sources. Once collected, the data needs a home, so it’s stored in databases, datawarehouses , or other storage systems, ensuring it’s easily accessible when needed.
his setup allows users to access and manage their data remotely, using a range of tools and applications provided by the cloud service. Cloud databases come in various forms, including relational databases, NoSQL databases, and datawarehouses. There are several types of NoSQL databases, including document stores (e.g.,
This process includes moving data from its original locations, transforming and cleaning it as needed, and storing it in a central repository. Data integration can be challenging because data can come from a variety of sources, such as different databases, spreadsheets, and datawarehouses.
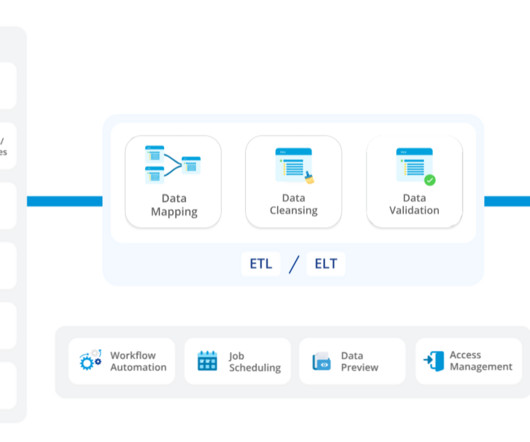
Transform and shape your data the way your business needs it using pre-built transformations and functions. Ensure only healthy data makes it to your datawarehouses via built-in data quality management. Automate and orchestrate your data integration workflows seamlessly.
Transform and shape your data the way your business needs it using pre-built transformations and functions. Ensure only healthy data makes it to your datawarehouses via built-in data quality management. Automate and orchestrate your data integration workflows seamlessly.
Compliance and Governance: Centralizing different data sources facilitates compliance by giving companies an in-depth understanding of their data and its scope. They can monitor data flow from various outlets, document and demonstrate data sources as needed, and ensure that data is processed correctly.
Data Validation: Astera guarantees data accuracy and quality through comprehensive data validation features, including data cleansing, error profiling, and data quality rules, ensuring accurate and complete data. to help clean, transform, and integrate your data.
It prepares data for analysis, making it easier to obtain insights into patterns and insights that aren’t observable in isolated data points. Once aggregated, data is generally stored in a datawarehouse. Data complexity, granularity, and volume are crucial when selecting a data aggregation technique.
4) Big Data: Principles and Best Practices Of Scalable Real-TimeData Systems by Nathan Marz and James Warren. Best for: For readers that want to learn the theory of big data systems, how to implement them in practice, and how to deploy and operate them once they’re built. Croll and B.
Other uses may include: Maintenance checks Guides, resources, training and tutorials (all available in BigQuery documentation ) Employee efficiency reviews Machine learning Innovation advancements through the examination of trends. (1). Big data analytics advantages. What is Big Data?” What is Google BigQuery? References.
A planned BI strategy will point your business in the right direction to meet its goals by making strategic decisions based on real-timedata. Save time and money: Thinking carefully about a BI roadmap will not only help you make better strategic decisions but will also save your business time and money.
Offers granular access control to maintain data integrity and regulatory compliance. Cons SAS Viya is one of the most expensive data analysis tools. Users find SAS documentation to be lacking, which complicates troubleshooting. Conducting a holistic analysis requires access to a consolidated data set.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. Empower your team to add new data sources on the fly.
We organize all of the trending information in your field so you don't have to. Join 57,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


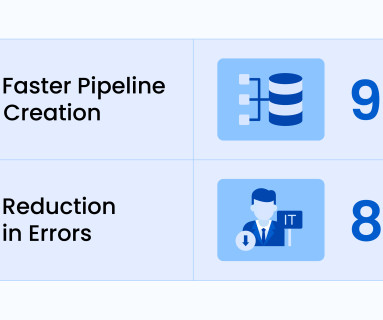






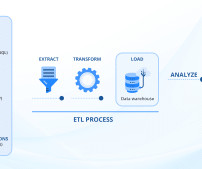




















Let's personalize your content