This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
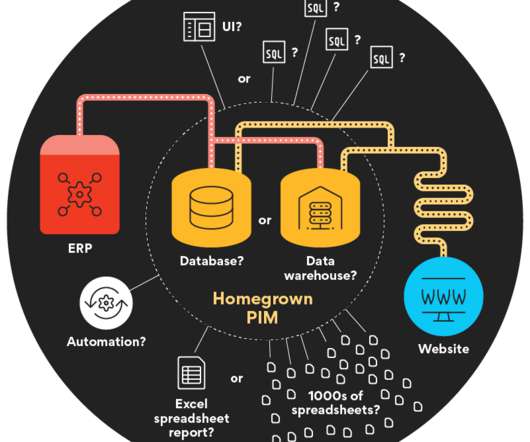
What is a “homegrown” product data system? Most manufacturing organizations have some kind of database or datawarehouse that holds lots and lots of company information. It’s likely pulling data from your ERP, multiple spreadsheets, multiple datawarehouses, and more. It may or may not have a user interface.
What is a “homegrown” product data system? Most manufacturing organizations have some kind of database or datawarehouse that holds lots and lots of company information. It’s likely pulling data from your ERP, multiple spreadsheets, multiple datawarehouses, and more. It may or may not have a user interface.
Still, the underlying premise is the same – in a post-digital transformation environment, companies need the ability to leverage a wide variety of technology components to support their business: IoT, cloud services, mobile devices, SaaS software, and traditional IT systems. Embedded and Edge Processing of Streaming Data.
These sit on top of datawarehouses that are strictly governed by IT departments. The role of traditional BI platforms is to collect data from various business systems. It is organized to create a top-down model that is used for analysis and reporting. I understand that I can withdraw my consent at any time.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
We organize all of the trending information in your field so you don't have to. Join 57,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





Let's personalize your content