This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about datavisualization and its role in the big data movement. Data is useless without the opportunity to visualize what we are looking for.
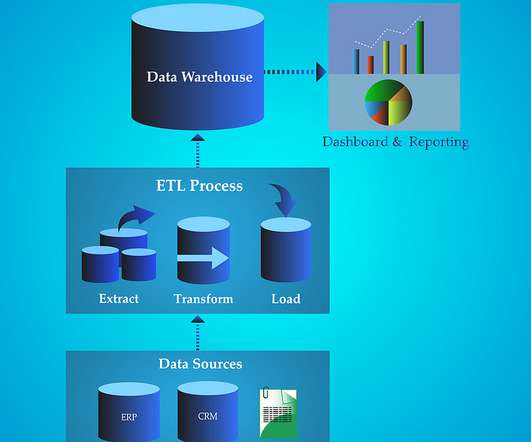
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or datawarehouse. If it’s not done right away, then later.
1) What Is DataQuality Management? 4) DataQuality Best Practices. 5) How Do You Measure DataQuality? 6) DataQuality Metrics Examples. 7) DataQuality Control: Use Case. 8) The Consequences Of Bad DataQuality. 9) 3 Sources Of Low-QualityData.
As the volume of available information continues to grow, data management will become an increasingly important factor in effective business management. Lack of proactive data management, on the other hand, can result in incompatible or inconsistent sources of information, as well as dataquality problems.
If you have had a discussion with a data engineer or architect on building an agile datawarehouse design or maintaining a datawarehouse architecture, you’d probably hear them say that it is a continuous process and doesn’t really have a definite end. What do you need to build an agile datawarehouse?
This can include a multitude of processes, like data profiling, dataquality management, or data cleaning, but we will focus on tips and questions to ask when analyzing data to gain the most cost-effective solution for an effective business strategy. 4) How can you ensure dataquality?
Completeness is a dataquality dimension and measures the existence of required data attributes in the source in data analytics terms, checks that the data includes what is expected and nothing is missing. Consistency is a dataquality dimension and tells us how reliable the data is in data analytics terms.
Understanding the key concepts of data warehousing, such as data integration, dimensional modeling, OLAP, and data marts, is vital for business analysts who are responsible for analyzing data and providing insights that drive business performance. What is Data Warehousing?
Airbyte vs Fivetran vs Astera: Overview Airbyte Finally, Airbyte is primarily an open-source data replication solution that leverages ELT to replicate data between applications, APIs, datawarehouses, and data lakes. Like other data integration platforms , Airbyte features a visual UI with built-in connectors.
Airbyte vs Fivetran vs Astera: Overview Airbyte Finally, Airbyte is primarily an open-source data replication solution that leverages ELT to replicate data between applications, APIs, datawarehouses, and data lakes. Like other data integration platforms , Airbyte features a visual UI with built-in connectors.
It refers to the methods involved in accessing and manipulating source data and loading it into the target database. This inconsistency in data can be avoided by integrating the data into a datawarehouse with good standards. The datawarehouse design should accommodate both full and incremental data extraction.
Business leaders, developers, data heads, and tech enthusiasts – it’s time to make some room on your business intelligence bookshelf because once again, datapine has new books for you to add. We have already given you our top datavisualization books , top business intelligence books , and best data analytics books.
Reverse ETL (Extract, Transform, Load) is the process of moving data from central datawarehouse to operational and analytic tools. How Does Reverse ETL Fit in Your Data Infrastructure Reverse ETL helps bridge the gap between central datawarehouse and operational applications and systems.
With ‘big data’ transcending one of the biggest business intelligence buzzwords of recent years to a living, breathing driver of sustainable success in a competitive digital age, it might be time to jump on the statistical bandwagon, so to speak. One of the best books on building a BI system, hands down. click for book source**.
Siloed Data Challenges Financial institutions face several hurdles due to decentralized data. These challenges include: Legacy Systems: Outdated systems make it difficult to get the best data into your datawarehouse. Divergent data sources can lead to conflicting information, undermining accuracy and reliability.
AI-powered ETL tools can automate repetitive tasks, optimize performance, and reduce the potential for human error. By AI taking care of low-level tasks, data engineers can focus on higher-level tasks such as designing data models and creating datavisualizations.
There are several ETL tools written in Python that leverage Python libraries for extracting, loading and transforming diverse data tables imported from multiple data sources into datawarehouses. Astera Aspect Astera Python Data Integration Supports various data sources and destinations with ease.
Here are the critical components of data science: Data Collection : Accumulating data from diverse sources like databases, APIs , and web scraping. Data Cleaning and Preprocessing : Ensuring dataquality by managing missing values, eliminating duplicates, normalizing data, and preparing it for analysis.
Data wrangling tools are powerful solutions designed to simplify and automate the process of data preparation. They enable data professionals to clean, transform, and organize raw data efficiently, saving countless hours of manual work while ensuring dataquality and consistency.
Then there are: the vendors who provide the tools you need to create applications such as operating systems; and the SaaS applications you need to provide business value including business intelligence and datavisualization tools. Look for metadata management capabilities and ways to ensure dataquality.
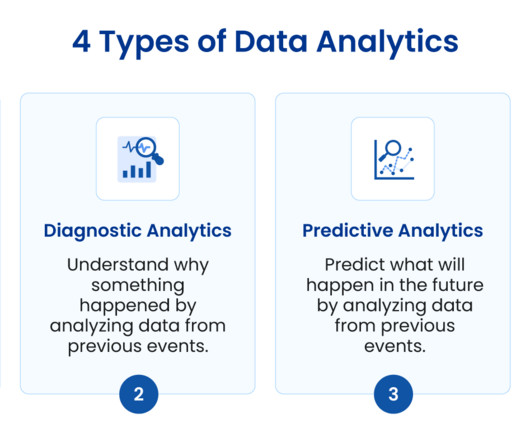
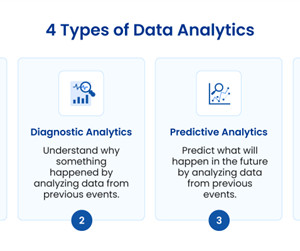
Statistical Analysis : Using statistics to interpret data and identify trends. Predictive Analytics : Employing models to forecast future trends based on historical data. DataVisualization : Presenting datavisually to make the analysis understandable to stakeholders.
Type of Data Mining Tool Pros Cons Best for Simple Tools (e.g., – Datavisualization and simple pattern recognition. Simplifying datavisualization and basic analysis. A key aspect of data preparation is the extraction of large datasets from a variety of data sources. Advanced Tools (e.g.,
Easy-to-Use, Code-Free Environment By eliminating the need for writing complex code, data preparation tools reduce the risk of errors. These tools allow users to manipulate and transform data without the potential pitfalls of manual coding. Manual export and import steps in a system can add complexity to your data pipeline.
Best for: the seasoned BI professional who is ready to think deep and hard about important issues in data analytics and big data. An excerpt from a rave review: “…a tour de force of the datawarehouse and business intelligence landscape. Khan Analytic Philosophy: A Very Short Introduction by Michael Beaney.
One of the most valuable aspects of self-serve business intelligence is the opportunity it provides for data and analytical sharing among business users within the organization. When considering the advantages of data popularity and sharing, one must also consider that not all popular data will be high-qualitydata (and vice versa).
One of the most valuable aspects of self-serve business intelligence is the opportunity it provides for data and analytical sharing among business users within the organization. When considering the advantages of data popularity and sharing, one must also consider that not all popular data will be high-qualitydata (and vice versa).
One of the most valuable aspects of self-serve business intelligence is the opportunity it provides for data and analytical sharing among business users within the organization. When considering the advantages of data popularity and sharing, one must also consider that not all popular data will be high-qualitydata (and vice versa).
This should also include creating a plan for data storage services. Are the data sources going to remain disparate? Or does building a datawarehouse make sense for your organization? Clean data in, clean analytics out. Cleaning your data may not be quite as simple, but it will ensure the success of your BI.
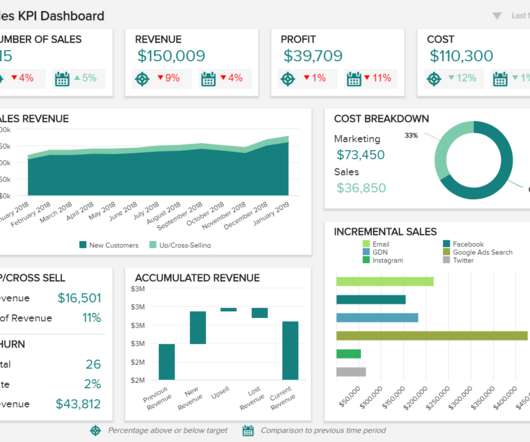
Data analysis tools are software solutions, applications, and platforms that simplify and accelerate the process of analyzing large amounts of data. They enable business intelligence (BI), analytics, datavisualization , and reporting for businesses so they can make important decisions timely.
Source: Gartner As companies continue to move their operations to the cloud, they are also adopting cloud-based data integration solutions, such as cloud datawarehouses and data lakes. Establish and enforce dataquality rules to ensure clean and consistent data across all environments.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
The quick and dirty definition of data mapping is the process of connecting different types of data from various data sources. Data mapping is a crucial step in data modeling and can help organizations achieve their business goals by enabling data integration, migration, transformation, and quality.
Existing applications did not adequately allow organizations to deliver cost-effective, high-quality interactive, white-labeled/branded datavisualizations, dashboards, and reports embedded within their applications. Join disparate data sources to clean and apply structure to your data.
These include data privacy and security concerns, model accuracy and bias challenges, user perception and trust issues, and the dependency on dataquality and availability. Data Privacy and Security Concerns: Embedded predictive analytics often require access to sensitive user data for accurate predictions.
Logi Symphony harnesses the strengths of two recent insightsoftware acquisitions, Logi Analytics and Dundas BI, to enable software teams to rapidly design, build, and embed interactive dashboards, pixel-perfect reports and datavisualizations with fast connectivity and access to modern data infrastructure.
Having accurate data is crucial to this process, but finance teams struggle to easily access and connect with data. Improve dataquality. Some functional areas use business intelligence and datavisualization tools, but operate in isolation with their own data sets, driving decisions related to that function only.
Moving data across siloed systems is time-consuming and prone to errors, hurting dataquality and reliability. Unleash the power of storytelling by showcasing your ESG achievements with engaging visuals. Manual processes and juggling multiple tools won’t cut it under the ever-changing CSRD regulations.
About Logi Symphony Logi Symphony enables software teams to rapidly design, build, and embed interactive dashboards and datavisualizations with fast connectivity and access to modern data infrastructure. Connect to any data source. Align data with ETL, data performance, dataquality, and data structure.
We organize all of the trending information in your field so you don't have to. Join 57,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content