This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Online Analytical Processing (OLAP) is a term that refers to the process of analyzing data online. Data processing and analysis are usually done with a simple spreadsheet, which has data values organized in a row and column structure. Several or more cubes are used to separate OLAP databases.
You can’t talk about data analytics without talking about datamodeling. The reasons for this are simple: Before you can start analyzing data, huge datasets like data lakes must be modeled or transformed to be usable. Building the right datamodel is an important part of your data strategy.
Enterprises will soon be responsible for creating and managing 60% of the global data. Traditional datawarehouse architectures struggle to keep up with the ever-evolving data requirements, so enterprises are adopting a more sustainable approach to data warehousing. Best Practices to Build Your DataWarehouse .
Teradata is based on a parallel DataWarehouse with shared-nothing architecture. Data is stored in a row-based format. It supports a hybrid storage model in which frequently accessed data is stored in SSD whereas rarely accessed data is stored on HDD. Not being an agile cloud datawarehouse.
Among the key players in this domain is Microsoft, with its extensive line of products and services, including SQL Server datawarehouse. In this article, we’re going to talk about Microsoft’s SQL Server-based datawarehouse in detail, but first, let’s quickly get the basics out of the way.
Among the key players in this domain is Microsoft, with its extensive line of products and services, including SQL Server datawarehouse. In this article, we’re going to talk about Microsoft’s SQL Server-based datawarehouse in detail, but first, let’s quickly get the basics out of the way.
Teradata is based on a parallel DataWarehouse with shared-nothing architecture. Data is stored in a row-based format. It supports a hybrid storage model in which frequently accessed data is stored in SSD whereas rarely accessed data is stored on HDD. The BYNET interconnect supports up to 512 nodes.
What is a Cloud DataWarehouse? Simply put, a cloud datawarehouse is a datawarehouse that exists in the cloud environment, capable of combining exabytes of data from multiple sources. A cloud datawarehouse is critical to make quick, data-driven decisions.
However, managing reams of data—coming from disparate sources such as electronic and medical health records (EHRs/MHRs), CRMs, insurance claims, and health-tracking apps—and deriving meaningful insights is an overwhelming task. Given the critical nature of medical data, there are several factors to be considered for its management.
As data warehousing technologies continue to grow in demand , creat ing effective datamodels has become increasingly important. However, creating an OLTP datamodel presents various challenges. Well, there’s a hard way of designing and maintaining datamodels and then there is the Astera’s way.
Data Lake Vs DataWarehouse Every business needs to store, analyze, and make decisions based on data. To do this, they must choose between two popular data storage technologies: data lakes and datawarehouses. What is a Data Lake? What is a DataWarehouse?
As data warehousing technologies continue to grow in demand , creat ing effective datamodels has become increasingly important. However, creating an OLTP datamodel presents various challenges. Well, there’s a hard way of designing and maintaining datamodels and then there is the Astera’s way.
Data and analytics are indispensable for businesses to stay competitive in the market. Hence, it’s critical for you to look into how cloud datawarehouse tools can help you improve your system. According to Mordor Intelligence , the demand for datawarehouse solutions will reach $13.32 billion by 2026. Ease of Use.
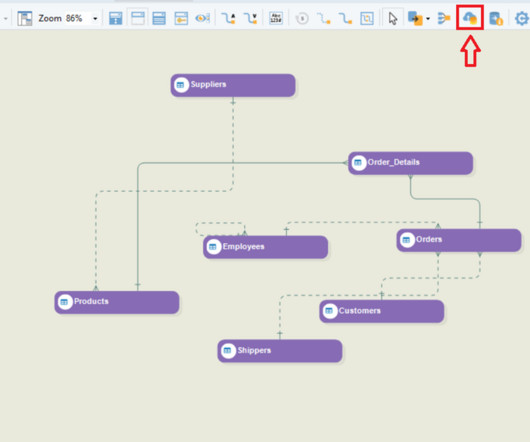
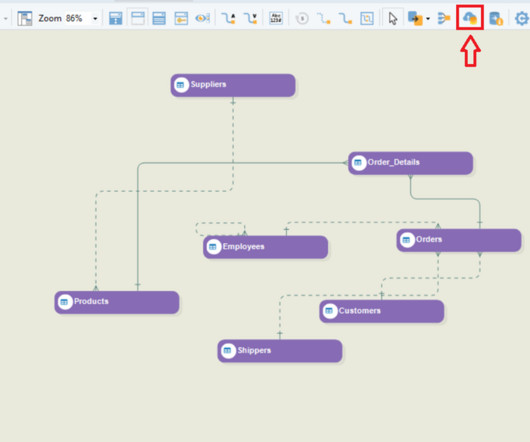
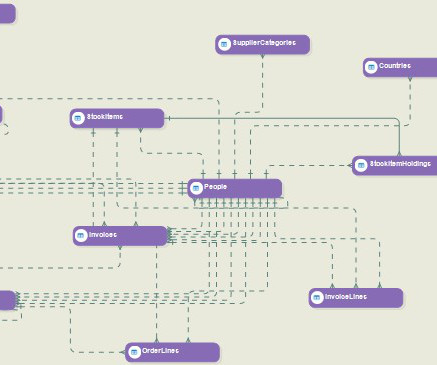
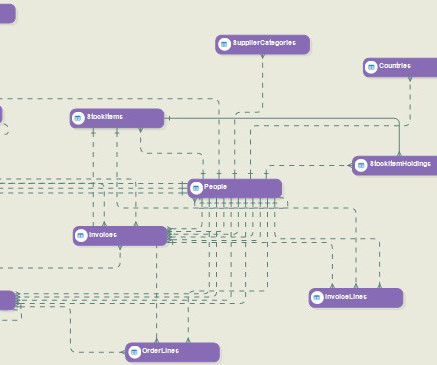
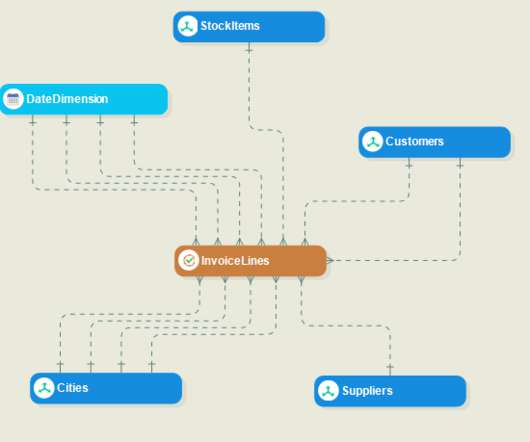
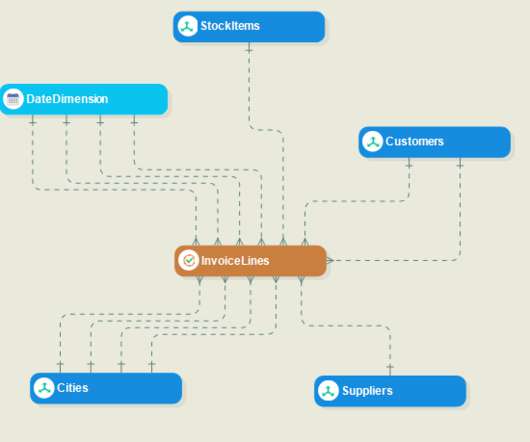
The primary purpose of your datawarehouse is to serve as a centralized repository for historical data that can be quickly queried for BI reporting and analysis. Datamodeling — which defines the database schema — is the heart of your datawarehouse . DataModel Verification.
The primary purpose of your datawarehouse is to serve as a centralized repository for historical data that can be quickly queried for BI reporting and analysis. Datamodeling — which defines the database schema — is the heart of your datawarehouse . Develop and deploy high-volume datawarehouses.
Data analytics is the science of examining raw data to determine valuable insights and draw conclusions for creating better business outcomes. Data Cleaning. DataModeling. Conceptual DataModel (CDM) : Independent of any solution or technology, represents how the business perceives its information. .
Even though technology transformation is enabling accelerated progress in data engineering, analytics deployment, and predictive modeling to drive business value, deploying a data strategy across cloud systems remains inefficient and cumbersome for CIOs. One of the key obstacles is data access.
Kimball-style dimensional modeling has been the go-to architecture for most datawarehouse developers over the past couple of decades. The questions that arise, however, are the following: How easy is it to load and maintain data in fact and dimension tables? And Is it worth the effort?
Reverse ETL (Extract, Transform, Load) is the process of moving data from central datawarehouse to operational and analytic tools. How Does Reverse ETL Fit in Your Data Infrastructure Reverse ETL helps bridge the gap between central datawarehouse and operational applications and systems.
With rising data volumes, dynamic modeling requirements, and the need for improved operational efficiency, enterprises must equip themselves with smart solutions for efficient data management and analysis. This is where Data Vault 2.0 It supersedes Data Vault 1.0, What is Data Vault 2.0? Data Vault 2.0
In this respect, we often hear references to “switching costs” and “stickiness.” Jet Analytics makes it easy for virtually anyone to quickly and easily design and populate a datawarehouse from Microsoft Dynamics AX, Microsoft D365 F&SCM, or any other product in the Microsoft Dynamics family.
What are data silos? Data silo is a term that refers to independent pockets of data within an organization. Often aligned to either business functions or IT systems, data silos are where only a limited group of people have access or knowledge of the data resources available. Data silos and company culture.
Data quality metrics are not just a technical concern; they directly impact a business’s bottom line. million annually due to low-quality data. Furthermore: 41% of datawarehouse projects are unsuccessful, primarily because of insufficient data quality.
Referring to the conceptual “edge” of the network, the basic idea is to perform machine learning (ML) analytics at the data source rather than sending the sensor data to a cloud app for processing. SkullCandy’s big data journey began by building a datawarehouse to aggregate their transaction data, reviews.
The right database for your organization will be the one that caters to its specific requirements, such as unstructured data management , accommodating large data volumes, fast data retrieval or better data relationship mapping. It’s a model of how your data will look.
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management? 2 – Data profiling.
OT is an umbrella term that describes technology components used to support a company’s operations – typically referring to traditional operations activities, such as manufacturing, supply chain, distribution, field service, etc.
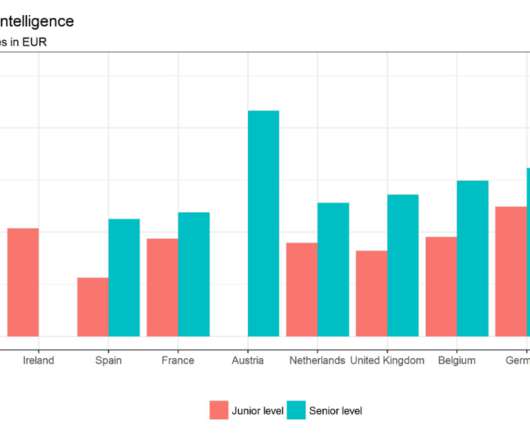
This could involve anything from learning SQL to buying some textbooks on datawarehouses. To help you improve your business intelligence engineer resume, or as it’s sometimes referred to, ‘resume BI engineer’, you should explore this BI resume example for guidance that will help your application get noticed by potential employers.
Additionally, data catalogs include features such as data lineage tracking and governance capabilities to ensure data quality and compliance. On the other hand, a data dictionary typically provides technical metadata and is commonly used as a reference for datamodeling and database design.
Data mapping is essential for integration, migration, and transformation of different data sets; it allows you to improve your data quality by preventing duplications and redundancies in your data fields. Data Migration Data migration refers to the process of transferring data from one location or format to another.
that gathers data from many sources. These sit on top of datawarehouses that are strictly governed by IT departments. The role of traditional BI platforms is to collect data from various business systems. It is organized to create a top-down model that is used for analysis and reporting. It’s all about context.
Predictive analytics refers to the use of historical data, machine learning, and artificial intelligence to predict what will happen in the future. Higher Costs: In-house development incurs costs not only in terms of hiring or training data science experts but also in ongoing maintenance, updates, and potential debugging.
We organize all of the trending information in your field so you don't have to. Join 57,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content