This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You may not even know exactly which path you should pursue, since some seemingly similar fields in the data technology sector have surprising differences. We decided to cover some of the most important differences between DataMining vs Data Science in order to finally understand which is which. What is Data Science?
What Is DataMining? Datamining , also known as Knowledge Discovery in Data (KDD), is a powerful technique that analyzes and unlocks hidden insights from vast amounts of information and datasets. What Are DataMining Tools? Type of DataMining Tool Pros Cons Best for Simple Tools (e.g.,
This data must be cleaned, transformed, and integrated to create a consistent and accurate view of the organization’s data. Data Storage: Once the data has been collected and integrated, it must be stored in a centralized repository, such as a datawarehouse or a data lake.
52% of IT experts consider faster analytics essential to datawarehouse success. However, scaling your datawarehouse and optimizing performance becomes more difficult as data volume grows. Leveraging datawarehouse best practices can help you design, build, and manage datawarehouses more effectively.
Read on to explore more about structured vs unstructured data, why the difference between structured and unstructured data matters, and how cloud datawarehouses deal with them both. Structured vs unstructured data. However, both types of data play an important role in data analysis.
52% of IT experts consider faster analytics essential to datawarehouse success. However, scaling your datawarehouse and optimizing performance becomes more difficult as data volume grows. Leveraging datawarehouse best practices can help you design, build, and manage datawarehouses more effectively.
52% of IT experts consider faster analytics essential to datawarehouse success. However, scaling your datawarehouse and optimizing performance becomes more difficult as data volume grows. Leveraging datawarehouse best practices can help you design, build, and manage datawarehouses more effectively.
It is used to answer the question, “Why did a certain event occur?” Exploratory Data Analysis. Exploratory data analysis is an approach used in data analytics terms to maximize the insights gained from data by investigating, analyzing, and summarizing data to uncover relevant patterns using visuals.
As evident in most hospitals, these information are usually scattered across multiple data sources/databases. Hospitals typically create a datawarehouse by consolidating information from multiple resources and try to create a unified database. Limitations of Current Methods.
When it comes to data modeling, function determines form. Let’s say you want to subject a dataset to some form of anomaly detection; your model might take the form of a singular event stream that can be read by an anomaly detection service. This design philosophy was adapted from our friends at Fishtown Analytics.).
Its versatility allows for its usage both as a database and as a datawarehouse when needed. The two complement each other so you can leverage your data more easily. PostgreSQL’s compatibility with Business Intelligence tools makes it a practical option for fulfilling your datamining, analytics, and BI requirements.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
The Challenges of Extracting Enterprise Data Currently, various use cases require data extraction from your OCA ERP, including data warehousing, data harmonization, feeding downstream systems for analytical or operational purposes, leveraging datamining, predictive analysis, and AI-driven or augmented BI disciplines.
Users Want to Help Themselves Datamining is no longer confined to the research department. Today, every professional has the power to be a “data expert.” These sit on top of datawarehouses that are strictly governed by IT departments. Standalone is a thing of the past. Privacy Policy.
We organize all of the trending information in your field so you don't have to. Join 57,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











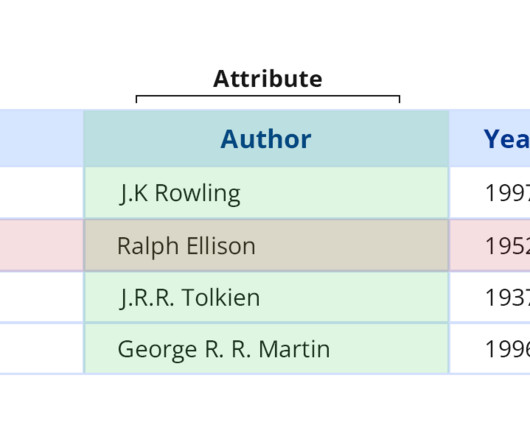


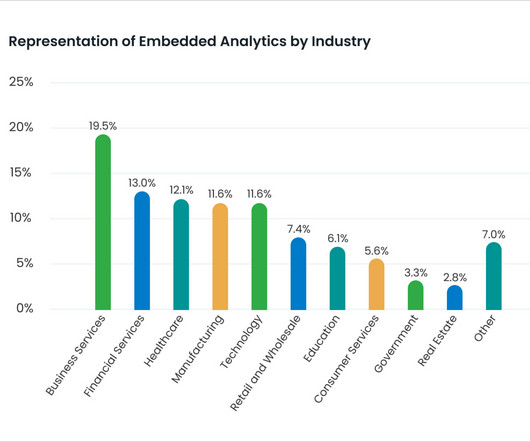


Let's personalize your content